Копипаст с Официального блога Mail.ru на хабре
Тяжелая жизнь антиспамеров или как это происходит на самом деле
Архитектура антиспама Mail.Ru

Собственный антиспам в Mail.Ru существует уже много лет. Желание разработать собственный продукт вполне объяснимо, т.к. на определенном этапе развития проекта требования к качеству и масштабируемости механизма борьбы со спамом стали слишком велики, чтобы их могли удовлетворить даже очень сильно кастомизированные «чужие» продукты. Конечно, какие-то сервисы и компоненты независимых поставщиков мы используем по-прежнему (например, для проверки писем на вирусную составляющую), но их роль сейчас уже не является определяющей.
Требования к нашему собственному антиспаму были очень понятными и логичными — максимальная скорость и точность срабатывания. Конечно, предела совершенству нет, отношения спамеров с их противниками представляют собой вечную борьбу щита и меча. Но сейчас мы уже с уверенностью можем говорить, что серьезно продвинулись к заветной цели и продолжаем наращивать «обороты».
Итак, как он выглядит и работает — современный(2011) антиспам Почты@Mail.Ru?
Прежде всего, еще на «подходе» к почтовым серверам все отправители проверяются по базе IP-адресов, замеченных в спам-рассылках. База динамически обновляется в режиме реального времени: одни IP «обеляются», другие попадают в «черный список». Соответственно, письма с IP-адресов с «подмоченной» репутацией не принимаются — таким образом нам удается отсечь большинство ботнетов.
Если IP отправителя нет в черном списке, то письмо принимается сервером и проходит проверку двумя системами антиспама: Kaspersky Anti-Spam (или коротко KAS) и разработанной в Mail.Ru системой фильтрации спама — MRAS (Mail.Ru Anti-Spam). Эти две системы всегда работают параллельно.
Название MRAS фигурирует, в частности, в служебных заголовках практически каждого письма, проходящего через почту Mail.Ru. Например, заголовок «X-Mras: Ok» говорит о том, что в данном письме не обнаружены спам-сигнатуры.
При выборе архитектуры MRAS мы воспользовались наиболее распространенным подходом: сбор образцов спам-писем, их анализ и генерация сигнатур. Если говорить упрощенно, то сигнатура — это кусок значимой информации в письме: номер телефона, ссылка, характерная фраза или ключевое слово и т.п. Оценка письма в MRAS производится по сигнатурам согласно простой логике: если в письме присутствуют сигнатуры, характерные для спам-рассылок — скорее всего, это письмо является спамом.
Отдельно стоит отметить систему распознавания графического спама. Каждая картинка, приходящая в письме, анализируется и также раскладывается на сигнатуры, которые участвуют в принятии решения. Например, антиспам уверенно определяет номера телефонов и адреса сайтов, написанных графически, причем алгоритм работает даже с искаженными и зашумленными изображениями.
Помимо сигнатур в MRAS существуют так называемые правила, описывающие более сложную логику. С помощью правил в MRAS можно создавать фильтры, учитывающие множественные признаки сообщений, включая служебные заголовки, параметры изображений, формат или паттерны ссылок, частотные и репутационные характеристики любой сущности в сообщении и т.д.
Когда мы выбирали движок для имплементации правил, обсуждались различные варианты. Основными требованиями были: высокая производительность, гибкость синтаксиса и легкая расширяемость. Обнаружили, что вышеперечисленным условиям соответствовал встраиваемый интерпретатор языка Lua. В результате мы получили мощный и гибкий инструмент, который пригодился не только для создания правил. Сейчас с помощью Lua-скриптов в MRAS реализуется значительная часть бизнес-логики, например, механизмы парсинга изображений и частотных шинглов, различные репутационные механизмы.
Откуда MRAS узнает о спам-рассылках?
Существует несколько источников образцов спама для MRAS. Основным источником являются жалобы пользователей, нажимающих в веб-интерфейсе почты кнопку «Это спам». Они группируются, проходят автоматическую фильтрацию и затем поступают в систему принятия решений.
Еще одним из важнейших источников являются ящики-ловушки — специально зарегистрированные и «засвеченные» в Интернете ящики, куда попадает только спам. Внешне они выглядят как ящики обычных пользователей — это могут быть аккаунты в Моем Мире и других социальных сетях, сообщения на форумах и в гостевых книгах и т.п. Недобросовестные рассыльщики, собирающие базу адресов по Интернету, с высокой долей вероятности зацепят несколько «ловушек» — и когда на них придет письмо, оно наверняка послужит основной для спам-сигнатуры.
Наконец, на третьем этапе находится группа аналитиков Почты@Mail.Ru, которые в режиме 24×7 в реальном времени анализируют полученные от пользователей жалобы на письма, возможно являющиеся спамом, контент ящиков-«ловушек» и т.д.
Далее — что происходит с письмом на выходе из MRAS? Проработав значимые сигнатуры писем, на выходе MRAS дает письму финальную оценку, которая может принимать одно из трех значений:
- письмо не спам
- письмо, возможно, является спамом
- письмо точно спам.
Такие же оценки выдает KAS. Если обе антиспам-системы считают письмо хорошим — письмо отправляется в папку «Входящие», если одна или обе системы пометили письмо как возможный спам — то в папку «Спам». Если хотя бы одна из систем уверена, что письмо — спам, то такое письмо не попадает к пользователю, а отправителю уходит сообщение о недоставке (bounce message).
Важно отметить, что эта же система обрабатывает и исходящие письма с серверов Mail.Ru. Так что если пользователь пытается отослать спам-письмо, ему приходит извещение о том, что послание не может быть отправлено.
Интересно отметить, что MRAS проверяет письмо не только на входе, но и через некоторое время после того, как оно попало в пользовательский ящик — это связано с тем, что новые данные о спам-рассылках могли изменить ситуацию и, соответственно, мнение системы. Поэтому если в тот момент, когда письмо обрабатывалось MRAS, оно не определялось как спам-рассылка, а через несколько минут — уже определилось, MRAS перекладывает письмо из «Входящих» в папку «Спам». Естественно, это происходит строго до того, как пользователь зашел в папку «Входящие» и увидел письма.
Все, что было сказано выше, составляет автоматическую систему фильтрации спама, которая работает для всех пользователей. Однако у разных пользователей разные предпочтения, поэтому недавно мы внедрили индивидуальную (персональную) составляющую спам-фильтрации.
Что нового(2011)?
Не секрет, что с массовым распространением социальных сетей, онлайн-игр, интернет-магазинов и прочих сервисов, активно общающихся со своей аудиторией посредством электронной почты, в ящиках пользователей начали скапливаться горы различных уведомлений. И проведенные нами исследования показывают, что для современных пользователей спам — уже далеко не только массовая рассылка про «печать визиток», «гринкарты» или «увеличение самизнаетечего». Спамом люди считают любое нежелательное письмо, будь то надоевшая рассылка с непрозрачной отпиской или давно неинтересный интернет-сервис, который с завидной регулярностью попадает во «Входящие».
Согласно внутренней статистике Mail.Ru, пользователи ежедневно получают по несколько десятков разнообразных рассылок от социальных сетей, магазинов и интернет-сервисов. Продвинутый пользователь легко избегает скопления рассылок во «Входящих» с помощью фильтров или черных списков. Для того чтобы облегчить жизнь всем остальным пользователям, мы внедрили персональный антиспам.
Теперь любой пользователь может в один клик раз и навсегда избавиться от надоевшей рассылки интернет сервиса, соц.сети или магазина — т.е. вполне легитимных сервисов. Достаточно выделить одно ненужное письмо и нажать кнопку «Это спам», после чего все письма от этого отправителя будут приходить уже в папку «Спам». И конечно, это не повлияет на доставку писем другим пользователям, речь в данном случае идет о сугубо индивидуальной настройке антиспам-механизма «под себя».
Кстати, у кнопки «Это спам» есть антипод, без которого механизм персонального антиспама был бы не полным. Кнопка «Это не спам», доступная для писем из папки «Спам», позволяет переместить во Входящие письмо, попавшее в Спам по ошибке и «обелить» адрес отправителя. В дальнейшем все письма от этого отправителя будут поступать во Входящие.
Разумеется, в реальности все несколько сложнее. При формировании индивидуальных черных и белых списков мы учитываем не только адрес отправителя, но и другие параметры письма. В противном случае, мы бы сделали слишком приятно отправителям спама, подделывающим заголовок From 😉
И конечно, кроме пополнения индивидуальных спам-фильтров, нажатия кнопок «Это спам» и «Это не спам» используется и для обучения общего антиспама. Так что, нажимая эти кнопки, пользователь делает лучше не только себе, но и всем остальным пользователям.
Кстати, как и следовало ожидать, кнопку «Это не спам» пользователи нажимают в 10-20 раз реже, чем «Это спам».
И наконец… как отправлять почту 😉
Многие из вас имеют прямое отношения к веб-разработке и, так или иначе, отправляют письма своим пользователям. Чтобы ваши письма доставлялись надежно, мы сформулировали рекомендации для отправителей. Их выполнение, конечно, не строго обязательно, однако делает мир лучше 😉 Рекомендации общего характера лежат по адресу http://help.mail.ru/mail-help/rules/general, а более конкретные технические требования — по адресу http://help.mail.ru/mail-help/rules/technical.
Главная задача почты — доставлять письма своим пользователям. Поэтому мы старательно боремся с ложными срабатываниями антиспама, когда они возникают. Если ваши письма не доходят до пользователей — пишите на [email protected]. Для того чтобы разобраться в проблеме, нужно приложить полную копию письма, которое вы отправляли (со всеми служебными заголовками), а также ответ о недоставке (тоже полностью).
Особенное внимание хочется обратить на механизмы, которые призваны компенсировать недостатки протоколов передачи электронной почты. Речь идет об указании корректных записей SPF и особенно о подписывании каждого сообщения с помощью DKIM, о котором не раз писали на хабре.
По сути, если все честные отправители будут использовать эти подходы — мировая ситуация со спамом радикально улучшится. Поэтому призываем вас скорее внедрить эти технологии, тем более что настроить это достаточно просто (вот например, документация для настройки DKIM в exim или одна из реализаций DKIM для postfix).
Сергей Мартынов,
Руководитель Почты@Mail.Ru

В этой статье я хочу рассказать о системе антиспама в Почте Mail.Ru и опыте работы с Tarantool в рамках этого проекта: в каких задачах мы используем эту СУБД, с какими трудностями и особенностями ее интеграции столкнулись, на какие грабли наступали, как набивали шишки и в итоге познали дзен.
Сначала краткая история антиспама. Внедрять антиспам Почта начала более десяти лет назад. Первым решением, которое использовалось для фильтрации, стал Антиспам Касперского в паре с RBL (Real-time blackhole list — список реального времени, содержащий IP-адреса, тем или иным образом связанные с рассылкой спама). В результате количество нежелательных писем снизилось, но из-за особенностей работы системы (инертности) такой подход не удовлетворял поставленным требованиям: быстро (в режиме реального времени) подавлять спам-рассылки. Немаловажным условием было быстродействие системы — пользователь должен получать проверенные письма с минимальной задержкой. Интегрированное решение не успевало за спамерами. Спам-рассыльщики очень динамично меняют (видоизменяют) контент и модель своего поведения, когда видят, что их письма не доставляются до адресата, поэтому мириться с инертностью мы не могли. И начали разрабатывать свою собственную систему фильтрации спама.
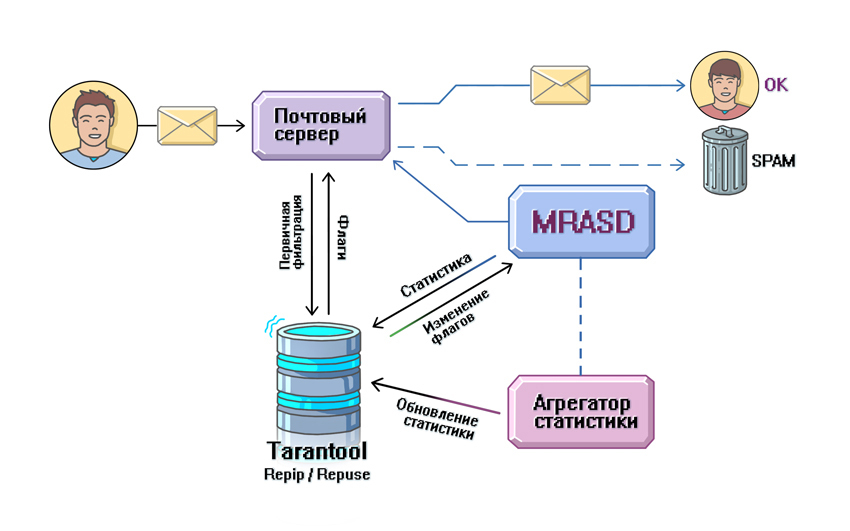
Следующим этапом в Почте Mail.Ru появился MRASD — Mail.Ru Anti-Spam Daemon. По сути он представлял собой очень простую систему. Письмо от клиента попадало на почтовый сервер Exim, проходило первичную фильтрацию c помощью RBL, после чего отправлялось в MRASD, где и совершалась вся «магия». Антиспам-демон разбирал сообщения на части: заголовки, тело письма. Дальше над каждой из них проводились простейшие нормализации текста: приведение к одному регистру, схожих по написанию символов к определенному виду (например, русская буква о и английская буква о превращались в один символ) и т. п. После того как нормализация выполнялась, извлекались так называемые сущности, или сигнатуры письма. Анализируя различные части почтовых сообщений, службы фильтрации спама блокируют на основании какого-либо содержания. Например, можно создать сигнатуру на слово «виагра», и все сообщения, которые содержат это слово, будут блокироваться. Другими примерами сущности служат URL’ы, картинки, вложения. Также во время проверки письма формируется его уникальный признак (fingerprint) — c помощью определенного алгоритма высчитывается множество хеш-функций для письма. По каждому хешу и сущности велась статистика (счетчики): сколько раз встречалась, сколько раз на нее жаловались, флаг сущности — SPAM/HAM (ham в терминологии антиспама — антоним термину spam, означающий, что проверяемое письмо не содержит spam-контента). На основе этой статистики принималось решение при фильтрации писем: когда хеш или сущность достигнут определенной частотности, сервер может заблокировать конкретную рассылку.
Ядро системы было написано на С++, а значимая часть бизнес-логики унесена в интерпретируемый язык Lua. Как я упоминал выше, спамеры — народ динамичный и быстро меняют свое поведение. На каждое изменение нужно уметь сразу же реагировать, именно поэтому для хранения бизнес-логики решили использовать интерпретируемый язык (не нужно каждый раз перекомпилировать систему и раскладывать на серверы). Другим требованием к системе было быстродействие — у Lua хороший показатель по скорости работы, вдобавок ко всему он легко интегрируется в C++.
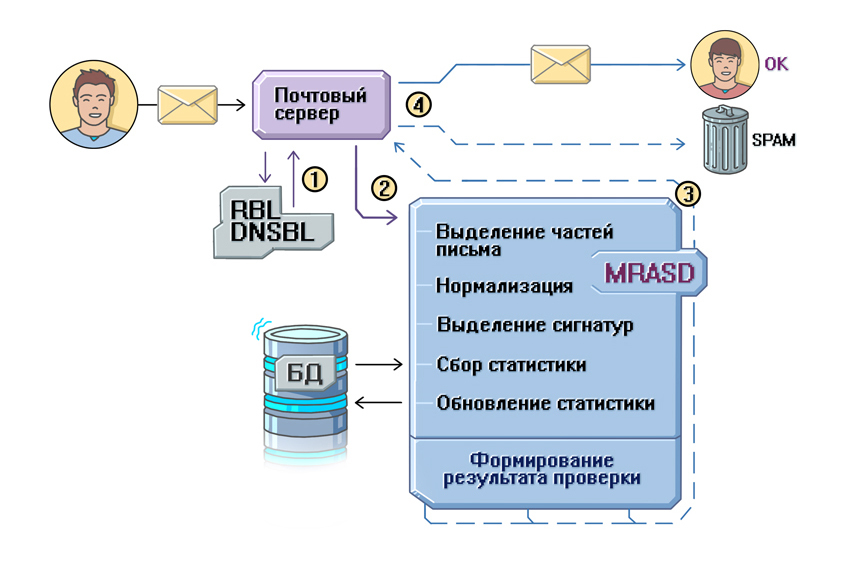
На рисунке выше проиллюстрирована упрощенная схема передачи письма: от отправителя оно попадает на сервер, проходит первичные проверки (1), если успешно, то передается на проверку MRASD (2). MRASD возвращает результат проверки на сервер (3), и на его основе письмо либо кладется в папку «Спам», либо отправляется пользователю во входящие.
Внедрение MRASD в десять раз снизило количество спам-сообщений, доставляемых пользователю. Время шло, система совершенствовалась, появлялись новые подсистемы, компоненты, внедрялись новые технологические инструменты. Система расширялась и становилась более сложной, задачи, решаемые командой антиспама, также становились все более разнообразными. Изменения не могли не сказаться на технологическом стеке, о котором я и расскажу.
Эволюция технологического стека
В начале развития почтовых сервисов поток писем, да и их контент был намного более скудным, нежели чем в настоящий момент, но и выбор инструментов, и вычислительные способности были, мягко говоря, другими. Из описанной выше «родительской» модели MRASD видно, что для функционирования системы требовалось сохранять разного рода статистическую информацию. При этом процент «горячих» (т. е. часто используемых) данных был высок, что, несомненно, накладывало определенные требования на хранилище данных. В итоге для хранения «холодных» (редко обновляемых) данных выбор остановился на MySQL. Оставался вопрос: какое решение выбрать для хранения горячей (выпечки) статистики? Проанализировав доступные варианты (их производительность и функциональные возможности для хранения горячих, но не критически важных данных), выбор остановили на Memcached — на тот момент это было уже достаточно стабильное решение. Но оставалась проблема с хранением горячих важных данных: у Memcached, как у любого кеша, есть свои недостатки, один из которых — отсутствие репликации, а также проблема с прогреванием кеша, когда он падает (очищается). В результате поисков пристанища для наших важных и горячих данных выбор пал на нереляционную key-value БД Kyoto Cabinet.
Шло время, нагрузки на почту, а как следствие — на антиспам росли. Появлялись новые сервисы, требовалось хранить все больше данных (Hadoop, Hypertable). К слову, в настоящий момент на пике количество обрабатываемых писем в минуту достигает значения в 550 тысяч (если усреднить этот показатель за сутки, то в среднем за минуту проверяется порядка 350 тысяч сообщений), объем анализируемых логов — более 10 Тб в день. Но вернемся в прошлое: несмотря на растущие нагрузки, требование к быстрой работе с данными (загрузка, сохранение) оставалось актуальным. И в какой-то момент Kyoto перестала справляться с необходимыми нам объемами. Кроме того, нам хотелось иметь более функционально богатый инструмент для хранения важных горячих данных. Словом, нужно было начинать крутить головой для поиска достойных альтернатив, которые были бы гибкими и легкими в использовании, производительными и отказоустойчивыми. В то время в нашей компании набирала популярность NoSQL БД Tarantool, которая была разработана в родных стенах и отвечала поставленным нами «хотелкам». К слову сказать, недавно, делая ревизию наших сервисов, я почувствовал себя археологом: наткнулся на одну из самых ранних версий — Tarantool/Silverbox. Попробовать эту базу данных мы решили потому, что заявленные benchmark’и покрывали наши объемы (точных данных о нагрузках на этот период нет), а также хранилище удовлетворяло наши запросы по отказоустойчивости. Немаловажный фактор — проект находился «под боком», и можно было быстро подкидывать свои задачи с помощью JIRA. Мы были в числе новичков, которые решили испытать у себя в проекте Tarantool, и думаю, что успешный опыт первопроходцев тоже нас подтолкнул к такому выбору.
Тогда началась наша «эра Тарантула». Он активно внедрялся и до сих пор внедряется в архитектуру антиспама. В настоящее время у нас можно найти очереди, реализованные на базе Tarantool, высоконагруженные сервисы по хранению всевозможной статистики: репутации пользователей (user reputation), репутации отправителей по IP (IP reputation), доверительной статистики по пользователю (karma) и т. д. Сейчас ведется работа по интеграции модернизированной системы хранения и работы со статистикой сущностей. Предугадывая вопросы о том, почему мы в нашем проекте зациклились на одном решении и не переходим на другие хранилища, скажу, что это не совсем так. Мы изучаем и анализируем конкурирующие системы, но в настоящий момент Tarantool успешно справляется с отведенными ему задачами и нагрузками в рамках нашего проекта. Внедрение новой (незнакомой, не используемой ранее) системы всегда чревато осложнениями, требует много времени и ресурсов. Tarantool же в нашем (да и не только) проекте хорошо изучен. Программисты и системные администраторы уже на нем собаку съели и знают тонкости работы и настройки системы, чтобы она была максимально эффективна. Плюс также и в том, что команда разработчиков постоянно совершенствует свой продукт и обеспечивает поддержку (да и близко сидит, что тоже очень удобно :)). Так, при внедрении нового решения, основанного на хранении данных в Tarantool, я очень быстро получал от ребят ответы на интересующие меня вопросы и необходимую помощь (об этом я расскажу чуть позже).
Дальше я проведу краткий обзор нескольких систем, основанных на этой СУБД, и поделюсь теми особенностями, с которыми пришлось столкнуться.
Краткий экскурс в системы, где используется Tarantool
Карма — это числовая характеристика, которая отражает степень доверия к пользователю. Задумывалась прежде всего как основа общей системы «кнута и пряника» для пользователя, построенной, не прибегая к сложным зависимым системам. Карма выступает в роли агрегатора данных, полученных от других репутационных систем. Идея системы проста: у каждого пользователя есть своя карма — чем она выше, тем больше мы доверяем пользователю, чем ниже, тем более жестко мы принимаем решения при проверке писем. Так, если отправитель посылает письмо с подозрительным контентом и имеет высокий рейтинг, письмо будет доставлено получателю. Низкая карма учитывается при принятии решения о спамности письма как пессимизирующий фактор. Эта система мне напоминает школьный журнал на экзамене. Отличнику зададут два-три дополнительных вопроса и отпустят на каникулы, а двоечнику придется попотеть, чтобы получить положительную оценку.
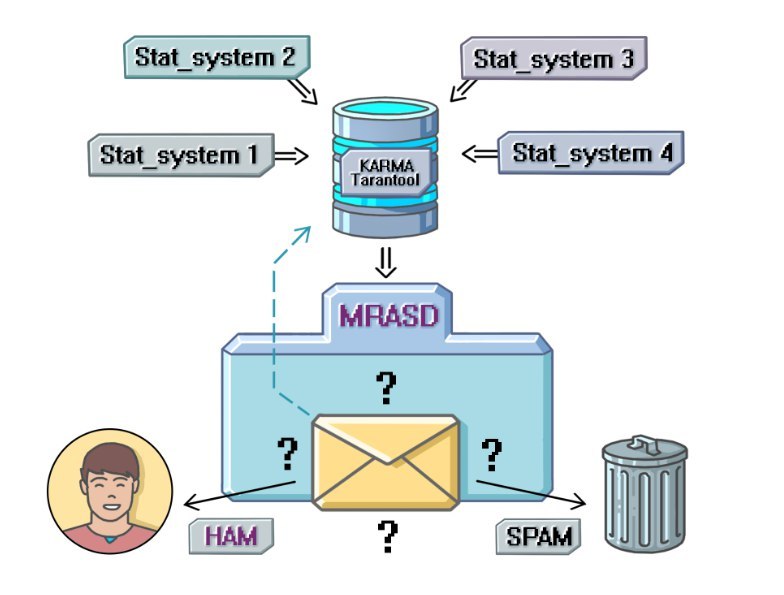
Tarantool, хранящий данные, связанные с кармой, работает на одной машине. Ниже представлен график количества запросов, выполняемых на одном инстансе кармы в минуту.
RepIP/RepUser
RepIP и RepUser (reputation IP и reputation user) — высоконагруженный сервис, предназначенный для учета статистики об активности и действиях отправителей (пользователей) с конкретным IP, a также пользователя при работе с почтой за определенный временной интервал. С помощью данной системы мы можем сказать, сколько писем отправил пользователь, сколько из них было прочитано, а сколько помечено как спам. Особенность системы заключается в том, что при анализе поведения мы видим не мгновенную картину (snapshot) активности, а развернутую во временном интервале. Почему это важно? Представьте, что вы переехали в другую страну, где нет средств связи, а ваши друзья остались на родине. И вот спустя несколько лет к вам в хижину протягивают интернет. Вы залезаете в социальную сеть и видите фотографию своего друга — он очень сильно изменился. Как много информации вы можете извлечь из снимка? Думаю, не очень. А теперь представьте, если бы вам показали видео, в котором видно, как ваш друг меняется, женится и т. п., — этакая видеобиография. Думаю, во втором случае вы получите гораздо более полное представление о его жизни. Аналогично и с анализом данных: чем больше информации мы имеем, тем более точно мы можем оценивать поведение пользователя. Можно увидеть закономерность в интенсивности рассылки, понять «привычки» рассыльщиков. На основе такой статистики каждому пользователю и IP-адресу ставится мера доверия к нему, а также устанавливается специальный флаг. Именно этот флаг используется при первичной фильтрации, которая отсеивает до 70% нежелательных сообщений еще к моменту подлета письма на сервер. Данная цифра показывает, насколько значим сервис, поэтому от него и требуется максимальная производительность и отказоустойчивость. И для хранения такой статистики мы также используем Tarantool.
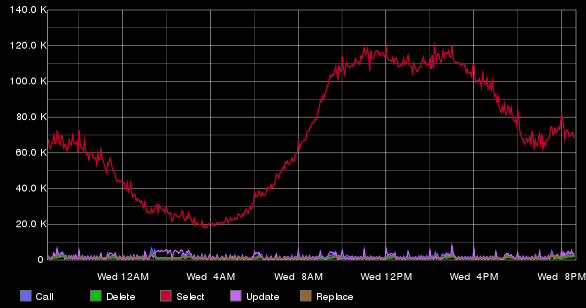
Статистика хранится на двух серверах по четыре инстанса Tarantool на каждом. Ниже приведен график с количеством выполняемых запросов на RepIP, усредненных за одну минуту.
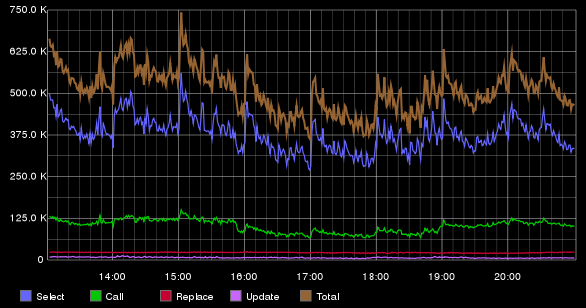
При реализации этого сервиса нам пришлось столкнуться с рядом задач, которые были связаны с настройкой Tarantool. От описанных ранее систем данную отличает то, что размер пакета со статистикой, который хранится в RepIP/RepUser, значительно больше: средний размер пакета — 471,97 байта (максимальный размер пакета — 16 Кб). Пакет можно разбить на две логические составляющие: маленькая «базовая» часть пакета (флаги, агрегированная статистика) и объемная статистическая часть (детальная статистика по действиям). Работа с целым пакетом приводит к тому, что возрастает утилизация сети и время загрузки с сохранения записи выше. Ряду систем нужна только базовая часть пакета, но как ее вытащить из тапла (tuple — так именуется запись в Tarantool)? На помощь нам приходят хранимые процедуры. Для этого нужно в файл init.lua дописать необходимую нам функцию и вызвать ее из клиента (начиная с версии 1.6 можно писать хранимые процедуры на С).
function get_first_five_fields_from_tuple(space, index, key)
local tuple = box.select(space, index, key)
-- Если запись не найдена — выходим
if tuple == nil then
return
end
-- Формируем нужный нам tuple
local response = {}
for i = 0, 4 do -- Индексация идет с нуля, а не с 1
table.insert(response, tuple[i])
end
return response
end
Проблемы версий до 1.5.20
Не обошлось и без приключений. После планового рестарта Tarantool клиенты (их было 500+) начинали стучаться на сервер и не могли подключиться (отваливались по тайм-ауту). Надо отметить, что не помогали и прогрессивные тайм-ауты — в случае неудачной попытки подключения время следующей попытки откладывается на некоторую увеличивающуюся величину. Проблема оказалась в том, что Tarantool за один цикл event-loop’а делал accept одному соединению (хотя в него долбились сотни). Проблему можно решить двумя способами: установкой новой версии 1.5.20 и выше или настройкой конфигурационного файла (нужно выключить опцию io_collect_interval, и тогда все будет хорошо). Команда разработчиков пофиксила эту проблему в кратчайшие сроки. В версии 1.6 она отсутствует.
RepEntity — репутация сущностей
В настоящий момент ведется интеграция нового компонента по хранению статистики для сущностей (URL, image, attach etc.) — RepEntity. Идея RepEntity похожа на описанную ранее RepIP/RepUser — она также позволяет иметь развернутую информацию о поведении сущностей, на основе которой принимается решение при фильтрации спама. Благодаря статистике RepEntity мы можем отлавливать рассылки спама, ориентируясь на сущности письма. Например, если рассылка включает «плохой» URL (содержащий спам-контент, ссылку на фишинговый сайт и т. п.), мы сможем быстрее заметить и подавить рассылку подобных писем. Почему? Потому что мы видим динамику рассылки этого URL’а и можем детектировать изменение его поведения, в отличие от «плоских» счетчиков.
Основным отличием (особенностью) RepEntity от системы репутации IP, помимо измененного формата пакета, является существенный рост нагрузки на сервис (увеличивается объем обрабатываемых и хранимых данных и количество запросов). Например, в письме может быть до сотни сущностей (в то время как IP не более десяти), на большую часть из которых нужно загрузить и сохранить полный пакет со статистикой. Отмечу, что за сохранение пакета отвечает специальный агрегатор, который предварительно накапливает статистику. Таким образом, в рамках этой задачи существенно возрастает нагрузка на СУБД, что требует аккуратной работы при проектировании и внедрении системы. Хочу особо обратить внимание, что при внедрении данного компонента используется Tarantool версии 1.5 (это вызвано особенностями проекта), и дальше речь будет идти об этой версии.
Первое, что было сделано, — оценка необходимого объема памяти для хранения всей этой статистики. Про важность данного пункта могут сказать цифры: на ожидаемой нагрузке увеличение размера пакета на один байт приводит к росту суммарно хранимой информации на один гигабайт. Таким образом, перед нами стояла задача максимально компактно хранить данные в tuple (как я упоминал выше, мы не можем хранить весь пакет в одной ячейке тапла, поскольку существуют запросы на извлечение части данных из пакета). При расчете объема хранимых данных в Tarantool следует помнить, что есть:
- затраты на хранение индекса;
- затраты на хранение размера хранимых данных в ячейке тапла (1 байт);
- ограничение на размер тапла — 1 Мб (в версии 1.6).
Большое количество всевозможных запросов (чтений, вставок, удалений) приводило к тому, что Tarantool начинал тайм-аутить. Как выяснилось в ходе исследования, причина заключалась в том, что при частой вставке и удалении пакетов вызывалась сложная перебалансировка дерева (в качестве всех индексов использовался древовидный ключ — TREE). В этой БД какое-то свое хитрое самобалансирующееся дерево. При этом балансировка происходит не сразу, а при достижении какого-то условия «разбалансированности». Таким образом, когда дерево было «достаточно разбалансировано», запускалась балансировка, которая подтормаживала работу. В логах можно было увидеть сообщения типа Resource temporarily unavailable (errno: 11), которые исчезали через несколько секунд. Но во время этих ошибок клиент не мог получить интересующие его данные. Коллеги из Tarantool подсказали решение: использовать другой тип «деревянного» ключа — AVLTREE, который при каждой вставке/удалении/изменении производит перебалансировку. Да, число перебалансировок возросло, но их общая стоимость оказалась ниже. После того как новая схема была заправлена и был произведен рестарт БД, ошибка больше не проявлялась.
Другой трудностью, с которой нам пришлось столкнуться, была очистка устаревших записей. К сожалению, в Tarantool (насколько мне известно, в версии 1.6 так же) не получится выставить TTL (time to live) для указанной записи и забыть про ее существование, переложив заботы об ее удалении на хранилище данных. Но при этом есть возможность написать вычищающий процесс самому на Lua на основе box.fiber. С другой стороны, такой подход дает большую свободу действий: можно писать сложные условия удаления (не только по времени). Но, чтобы написать чистящий процесс правильно, тоже нужно знать и учитывать некоторые тонкости. Первый вытесняющий процесс (cleaning fiber), который я написал, люто тормозил систему. Дело в том, что количество данных, которые мы можем удалить, значительно меньше общего числа записей. Для того чтобы уменьшить число записей — кандидатов на удаление, я ввел вторичный индекс по интересующему меня полю. После чего написал файбер, который обходил всех кандидатов (у которых время изменения меньше заданного), проверял дополнительные условия для удаления (например, что флаг записи не выставлен) и, в случае если оба условия выполнялись, удалял запись. Когда я тестировал без нагрузки, все прекрасно работало. С низкой нагрузкой тоже все шло как по маслу. Но как только я приблизился к половинной от ожидаемой нагрузки — возникли проблемы. У меня начали тайм-аутить запросы. Я понял, что где-то дал маху. Стал разбираться и осознал, что мое представление о том, как работает файбер, было неправильным. В моем мире файбер был отдельным потоком, который никаким образом (кроме переключения контекста) не должен был влиять на прием и обработку запросов от клиентов. Но позже я выяснил, что файбер использует тот же event-loop, что и тред по обработке запросов. Таким образом, итерируясь в цикле по большому числу записей, без операции удаления я просто «блокировал» event-loop, и запросы от пользователей не обрабатывались. Почему я упомянул операцию delete? Потому что каждый раз, когда выполнялся delete, происходил yield — операция, которая «разблокирует» event-loop и позволяет обработать следующее событие. Отсюда я сделал вывод, что в случае, если n операций (где n нужно искать эмпирически — я взял 100) выполнялось без yield, необходимо делать форсированный yield (например, wrap.sleep(0)). Также следует учесть, что при удалении записи может происходить перестроение индекса и, итерируясь по записям, можно пропустить часть данных для удаления. Поэтому есть еще один вариант удаления. Можно в цикле делать select небольшого количества элементов (до 1000) и итерироваться по этой 1000 элементов, удаляя ненужные и запоминая последний неудаленный. А после этого на очередной итерации выбрать следующую 1000, начиная с последнего неудаленного.
local index = 0 -- Номер индекса, по которому будут выбираться ключи
local start_scan_key = nil -- Первый индекс, с которого будем выбирать
local select_range = 1000 -- Количество записей, которое будем выбирать в select_range
local total_processd = 0 -- Количество обработанных записей (tuple)
local space = 0 -- Номер спейса
local yield_threshold = 100 -- Разрешенное количество запросов, которые не вызывают yield
local total_records = box.space[space]:len() -- Общее число записей в спейсе
while total_processed < total_records do
local no_yield = 0
local tuples = { box.space[space]:select_range(index, select_range, start_scan_key) }
for _, tuple in ipairs(tuples) do -- Итерируемся по tuples
local key = box.unpack('i', tuple[key_index_in_tuple])
if delete_condition then
box.delete(space, key) -- delete делает yield
no_yield = 0
else
no_yield = no_yield + 1
if no_yield > yield_threshold then
box.fiber.sleep(0) -- Насильно делаем yield
end
start_scan_key = key -- Обновляем последний неудаленный ключ
end
total_processed = total_processed + 1
done
Также в рамках данной работы была попытка внедрить решение, которое помогло бы безболезненно производить решардинг в будущем, но опыт оказался неудачным, реализованный механизм нес в себе большой overhead, и в итоге от механизма решардинга отказались. Ждем появление решардинга в новой версии Tarantool.
Best practice:
Можно добиться еще большей производительности, если отключить xlog’и. Но стоит учесть, что начиная с этого момента Tarantool будет выполнять роль кеша, со всеми вытекающими последствиями (я говорю об отсутствии репликации и прогревании данных после рестарта). Не стоит забывать и о том, что остается возможность делать периодически snapshot и при необходимости восстановить данные из него.
В случае если несколько Tarantool работают на одной машине, то для увеличения производительности стоит «прибивать» каждый из них к ядрам. Например, если у вас 12 физических ядер, то не стоит поднимать 12 инстансов (нужно помнить о том, что у каждого Tarantool, помимо исполняющего треда, есть еще VAL-тред).
Чего не хватает:
- Шардинга.
- Кластерного подхода с возможностью динамической конфигурации кластера, например в случае добавления узлов или выхода узла из строя, аналогичного для MongoDB(mongos), Redis (redis sentinel).
- Возможности задания TTL (time to live) для записей.
Подводя итоги
Tarantool играет важную роль в системе антиспама, на нем завязано множество ключевых высоконагруженных сервисов. Готовые коннекторы позволяют легко использовать его в разных компонентах, написанных на разных языках. Tarantool хорошо зарекомендовал себя: за время использования БД в проекте не возникало серьезных проблем, связанных с ее работой и стабильностью при решении поставленных задач. Напомню, что есть ряд тонкостей, которые нужно учитывать при настройке БД (особенности для версии 1.5) для ее эффективной работы.
Немного о планах на будущее:
- Увеличение числа сервисов в проекте, работающих с Tarantool.
- Миграция на Tarantool 1.6.
- Также планируем использовать Sophia, в том числе и для задачи repentity, поскольку количество действительно горячих данных не так велико.